
Grab yourself a cup of coffee (or two) and buckle up, because we’re doing maths today.
Again.
Back it on up...
A quick refresher from last time: I pulled data from 50 keyword-targeted articles written on Brafton[1]’s blog between January and June of 2018.
We used a technique of writing these articles[2] published earlier on Moz that generates some seriously awesome results (we’re talking more than doubling our organic traffic in the last six months, but we will get to that in another publication).
We pulled this data again… Only I updated and reran all the data manually, doubling the dataset. No APIs. My brain is Swiss cheese.
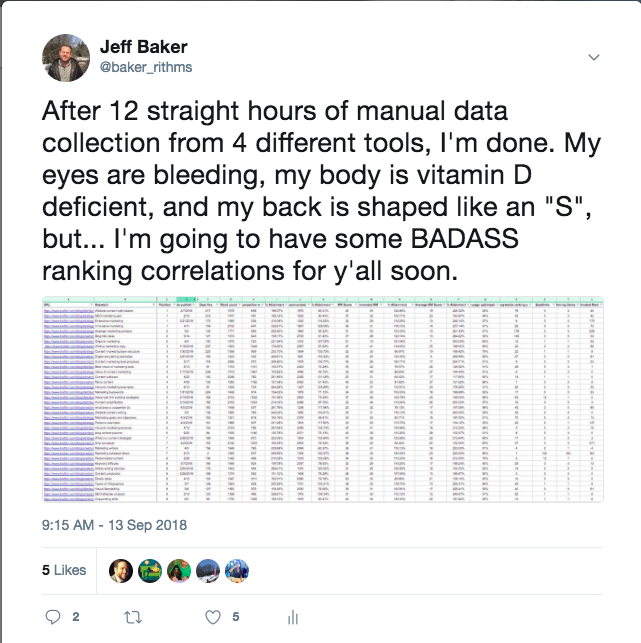
We wanted to see how newly written, original content performs over time, and which factors may have impacted that performance.
Why do this the hard way, dude?
“Why not just pull hundreds (or thousands!) of data points from search results to broaden your dataset?”, you might be thinking. It’s been done successfully quite a few times!
Trust me, I was thinking the same thing while weeping tears into my keyboard.
The answer was simple: I wanted to do something different from the massive aggregate studies. I wanted a level of control over as many potentially influential variables as possible.
By using our own data, the study benefited from:
- The same root Domain Authority across all content.
- Similar individual URL link profiles (some laughs on that later).
- Known original publish dates and without reoptimization efforts or tinkering.
- Known original keyword targets for each blog (rather than guessing).
- Known and consistent content depth/quality scores (MarketMuse).
- Similar content writing[3] techniques for targeting specific keywords for each blog.
You